本文共 1893 字,大约阅读时间需要 6 分钟。
Matt Bostock在SRECON 2017欧洲大会的中,介绍了如何使用Prometheus实现对分布于全球的的监控。Prometheus是一种基于度量进行监控的工具,CloudFlare是一家CDN、DNS和DDoS防御(Mitigation)服务提供商。
\\基于度量的开源监控项目最早推出于2012年,它是(原生云计算基金会,Cloud Native Computing Foundation)的成员。Prometheus的动态配置和查询语言PromQL支持用户编写对告警的复杂查询。CloudFlare提供CDN(内容分发网络,Content Delivery Network)、分布式DNS和DDoS防御服务,这意味着其架构已扩展到全球范围。监控这样的架构及网络无疑是一件复杂的工作。在演讲中,Bostock介绍了Prometheus在其中发挥的作用。在CloudFlare,前期部署的Nagios的职能已有87%被Prometheus所替代。
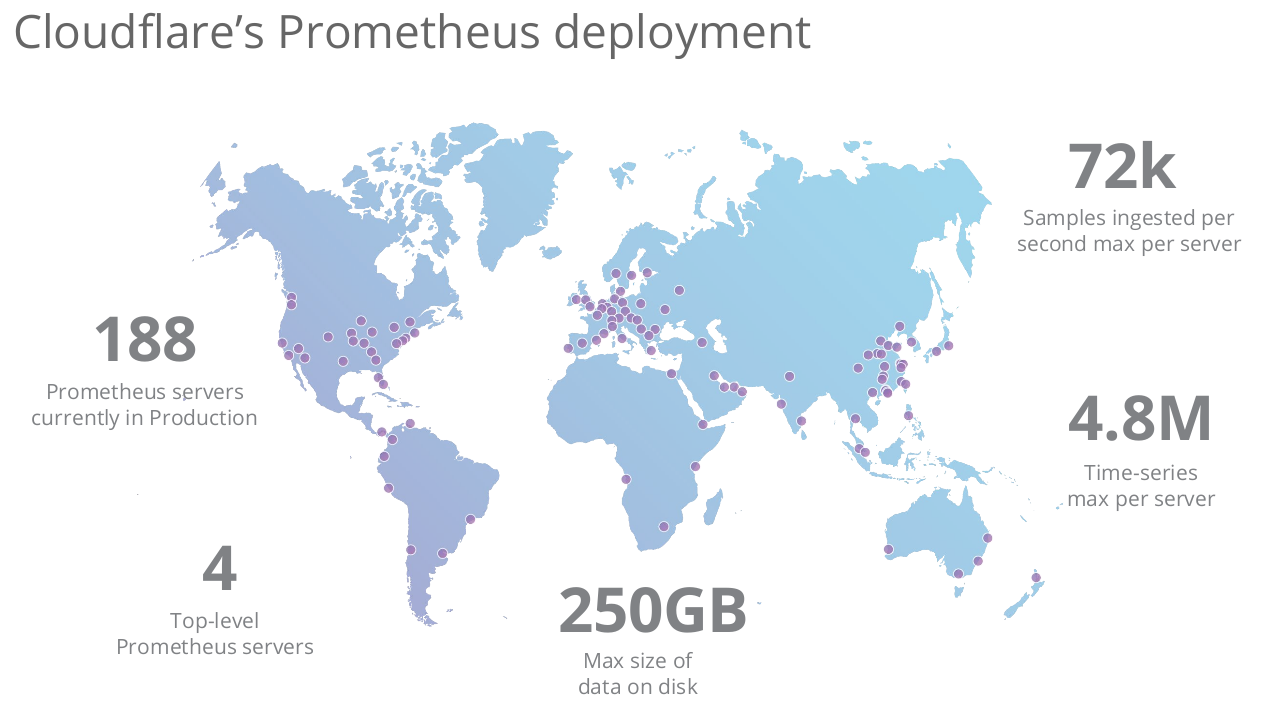
\\CloudFlare提供类似于Anycast所提供的CDN服务。使得DNS查询可以被最接近用户的服务器所处理,使得内容可以从距离用户最近的服务提供。作为原始Web站点和用户之间的中介,CloudFlare还检查访问者的流量中是否存在有威胁的模式。它提供了跨150个国家的116个数据中心,每秒处理500万次HTTP请求,120万次DNS请求,占全球因特网请求的10%。每个入网点(PoP,Point-Of-Presence)提供HTTP、DNS、DDoS防御和键值存储服务。截至演讲时,有188台运行在生产环境中的Prometheus服务器需要监控。
\\
图片来源:
\\Prometheus是基于度量的,也就是说它采集时序度量,并基于度量构建其余的特性。它工作于Pull模式下,每台监控服务器运行一个称作“exporter”的进程,通过HTTP发布所采集的度量。CloudFlare为每个服务域部署了一个exporter,使用它们采集系统(例如CPU、内存、TCP、磁盘等)、网络(例如HTTP、Ping等)、本地匹配(错误信息)和容器/命名空间的度量。其中,exporter使用了Google的开源项目采集容器/命名空间的度量。Prometheus并不会永久地保存所有数据,因为它更于“此时此地”(here-and-now)的监控情况。数据不做,并在CloudFlare配置中保存15天。
\\在CloudFlare的核心数据中心,服务包括日志访问、分析业务,以及使用Marathon、Mesos、Chronos、Docker、Sentry、Ceph(用于存储)、Kafka、Spark、Elasticsearch和Kibana等技术栈构建的API。Prometheus在每个PoP通过exporter查询服务器和服务获取度量。每个PoP的高可用性是由使用多个Prometheus服务提供的。
\\Prometheus的报警管理称为“Alertmanager”。CloudFlare的部署中包括一个Alermanager,由每个Prometheus服务器推送事件,并考虑了配置的高可用性。报警基于历史数据做测试,确保服务的正确执行的。等新兴监控工具也包括类似的特性。为提供更好的报警服务,其它的一些特性还包括了描述性的名称、简单易用性和一些可使接收者立刻采取行动的信息。
\\CloudFlare团队使用实现JIRA工单系统与Alertmanager的集成。JIRA可以用户定制工作流,使得报警监控中可以包括一些监控工作流特定的用户定制状态。另一个称为的工具接收报警,并将报警信息集成到Elasticsearch索引中,用于进一步的检索和分析。CloudFlare已为Alertmanger构建了自己的仪表盘,称为“”。
\\那么Prometheus是如何监控自身情况的?这有两种实现方法。一种是混合方法,即在同一数据中心中,由一个Prometheus去监控另一个Prometheus。另一种方法是自顶向下的方法,由顶层Prometheus服务器监控位于数据中心层面的Prometheus服务器。
\\CloudFlare SRE团队的经验是,尽早对环境和集群等的标签和组身份做标准化;其它一些经验是关于如何创建可视化,以及从同行和利益相关者生成买入。经验指出,团队的尽早参与将有助于服务与监控系统的更快整合。而报警本身则需要多次迭代进行调整和改进,这是一个开展中的过程。
\\查看英文原文:
转载地址:http://hrvkx.baihongyu.com/